학술저널 정리 : 대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제 STEP 2
크리스마스와 신년 사이의 그 간격의 날짜들은 특별한 느낌이 든다.
다시 한번 열심히 살기 위해 읽었던 저널을 정리하고자 한다.
대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제
대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제
송용주. (2011). 대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제. 정보과학회지, 29(5), 37-44.
대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제 STEP 1
대용량, 클라우드 서버 환경에서 DBMS가 고민해야할 문제 STEP 2
목차
- DBMS 변혁의 시기
- 쏟아져 나오는 대응책들
- 차세대 DBMS의 고민
- 새로운 이슈
- 결론
차세대 DBMS의 고민
고려해야할 특성
- 대용량 데이터
저장 공간과 처리 능력의 동시 확장이 필요 - 잦은 장애
대용량 데이터 때문에 수십,수백대의 서버를 묶어야 하는 환경에선 서버 장애 확률이 급격히 증가한다.
잦은 장애를 가정한 다중화 기술이 필요 - 서비스 작성의 편의성
성능이 좋아도 응용 서비스의 생산성이 떨어지면 본말전도!
사용의 편의성을 고려
기능적 요구 사항
- 수평적 확장
하루마다 수십TB 이상 생성되는 데이터를 수직적 확장으로 따라잡는 것은 불가능하므로 수평적 확장이 필요 - 병렬 처리
대용량 데이터 적재에는 필연적으로 처리 속도의 비약적인 향상이 필요
병렬 처리 도입시 데이터 정합성을 위해 Lock-ing이 필수
그러나 Locking 발생 시 성능의 선형 확장성을 보장할 수 없음 - 짧은 장애 복구 시간 (무정지 서비스)
일반적으로 복구 시간과 평소 성능은 반비례
네트워크 케이블로 확대되는 클러스터/틀라우드 환경에서는 장애 복구 시간 단축이 성능보다 더 중요할 수 있음
서비스 전체 정지 시간을 최소화 or 부분 복구가 가능하도록 시스템 설계하는 방법을 강구하자 - SQL 지원
현재 대용량 데이터 처리는 Data Mining, Machine Learning과 같은 학문인데 RDBMS와 동일한 SQL 환경을 지원하는 것이 필요 - Multi-row Transaction 지원
SQL이 API 면에서의 편의성이라면 Multi-row Transaction은 기능면에서의 편의성
대용량 데이터 처리가 필요한 서비스는 다양하고 복잡해질 것이고, 정합성 체크와 해결 코드를 지원하는 Multi-row Transaction 을 포기하면 안된다.
새로운 이슈
분산 시스템의 CAP 이론에서 볼 수 있듯이 모든 요구사항을 만족하는 정답은 존재하지 않는다.
차세대 RDBMS를 개발할 시 피해갈 수 없는 중요한 선택을 이야기한다.
- 트랜잭션/격리수준 (Isolation Level): 성능과의 타협
변경중인 데이터에 대한 읽기를 막음으로써 데이터 정합성을 보장
변경 중인 데이터에 대한 읽기를 ‘막는 방법’을 고안해야 한다.
1. 변경 중인 데이터에는 Lock을 걸어서 읽기를 막는 것
(장점)메모리를 적게 사용
(단점)대기 시간으로 인하여 병렬 처리에 부적합
2. 변경 전의 데이터로 되돌려서 읽는 것
(장점)읽기가 막히지 않음
(단점)메모리와 CPU를 상대적으로 많이 사용- 분산 시스템에서의 트랜잭션은 Two-Phase Commit (2PC)인 XA 라고 부르는 표준이 존재
Commit 이전에 Prepare 단계를 추가함으로써 정합성을 정확히 맞추지만,
필연적으로 속도가 느려지는 단점이 존재한다.
NoSQL 진영에서는 트랜잭션을 지원하지 않는 이유가 위의 이유 때문이다.
NoSQL의 single row 트랜잭션과 2PC 사이의 중간 지점의 방법을 이야기 해보자.- 2PC - commit wait 생략 방법 :
commit 메시지에 대한 응답을 기다리지 않고 사용자에게 commit 완료를 알린다.
prepare 상태인 데이터를 읽을 때는 commit 이 금방 올 것이라는 가정을 토대로 잠시 대기하도록 하여 정합성 문제를 해결 - 2PC - prepare 생략 방법 :
단순 Multi-node commit 으로 볼 수 있다.
고전적인 분산 시스템에서는 사용하기 매우 위험하지만,수백 대 단위의 클러스터 시스템에서는 시도해볼 수 있는 방법이다.
- 2PC - commit wait 생략 방법 :
- 분산 시스템에서의 트랜잭션은 Two-Phase Commit (2PC)인 XA 라고 부르는 표준이 존재
- Replication: 복구 시간과의 타협
장애가 잦은 환경에서 데이터 유실을 방지하기 위해서 데이터의 상시 복제는 필수적이다.
복제 방법을 알아보자.- 서버 단위 복제 (Active-Standby)
가장 단순한 형태의 복제 방식
데이터 복사본이 여러개 필요하기 때문에 장애가 잦고 불필요한 자원 소모를 최대한 줄이려 하는 클러스터/클라우드 환경에 부적합하다. - 묶음 단위 복제
서버 전체를 복제하지 않고 데이터의 일정 크기 묶음으로 나눠서 복제하는 방식
복사본만큼의 디스크 용량이 더 필요한 것은 동일하지만 작은 단위로 복제하면서 한 서버가 Active/Standby 묶음을 골고루 가지게 되어 부하 분배가 잘되는 장점을 가진다.
복사본만큼의 디스크 용량이 더 필요한 것은 동일하지만 작은 단위로 복제하면서 한 서버가 Active/Standby 묶음을 골고루 가지게 되어 부하 분배가 잘되는 장점을 가진다.
현재로서는 최선의 방식이나 Multi-row 트랜잭션과 맞물리면 문제가 발생하기에 완벽한 해법은 아니다.
- 서버 단위 복제 (Active-Standby)
- Global Lock
특정 구간을 20% 빠르게 하는 것 보다 Lock 구간을 10% 줄이는 것이 End-to-User 성능을 늘리는데 효과적일 만큼 이를 잘 해결해야 한다.
최종 시스템의 성능은 Global Lock 구간이 얼마나 짧은가로 판가름 날 것
결론
- 차세대 DBMS가 고민해야할 문제점
- 대용량 데이터를 저장하기 위해서는 수평적 확장성이 요구된다.
- 잦은 장애 환경에서는 복구 시간을 최소화해야 한다.
- 빠른 서비스 개발을 위해 SQL과 트랜잭션을 지원해야 한다.
설계 과정에서 가장 중요하고 어려운 선택은 성능-정합성-복구시간 사이의 적절한 균형점을 찾는 것이다.
이러한 일련의 과제들을 해소하기 위해서는 RDBMS 아키텍처에 근본적인 변화가 필요하다.
당분간은 고성능과 정합성을 추구하는 기존 RDBMS의 틀을 유지하면서 탄력적인 확장성으로 대용량의 데이터를 수용하는 아키텍처로의 진화를 꾀해야 한다.
비고
정리에 작성하진 않았지만 마지막 결론 부분에 갑자기 Tibero사의 국산 DBMS의 소개와 장점을 설명하여 한번 찾아봤다.
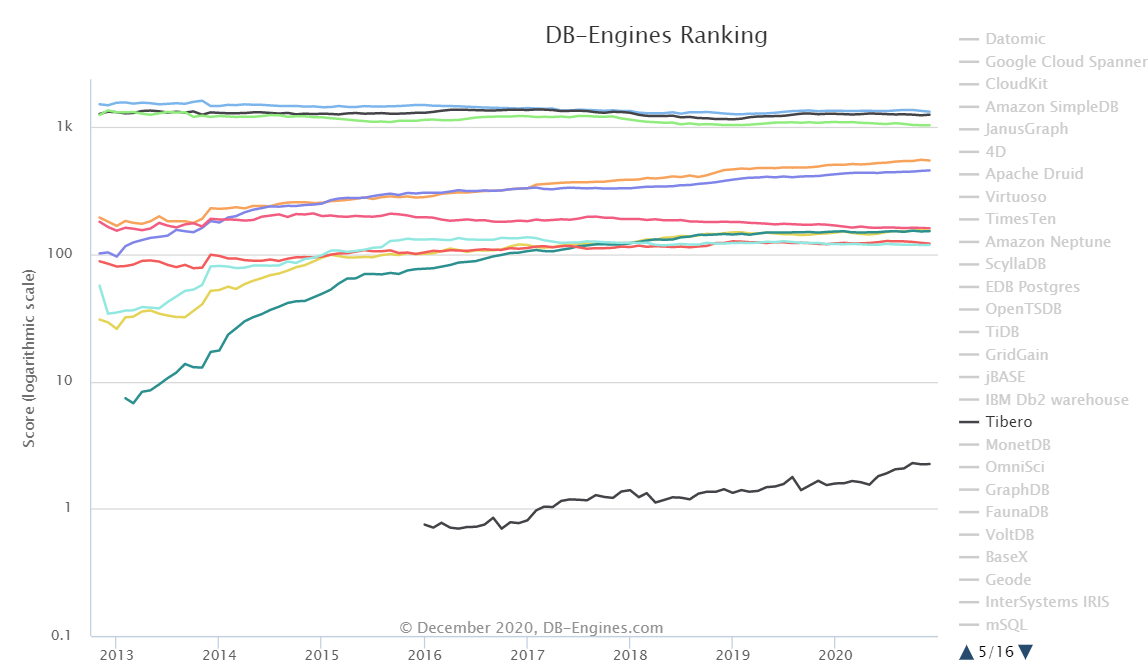
135위 안에 들어가 있는데, 그래프를 보면 꾸준한 성장세를 보이고 있는 듯 싶다.
이를 읽으면서 DBMS 의 요구 사항과 발전 방향성을 알게된 것 같다.
댓글남기기